Adding Search to Your Site with JavaScript
Static website generators like Gatsby and Jekyll are popular because they allow the creation of complex, templated pages that can be hosted anywhere. But the awesome simplicity of website generators is also limiting. Search is particularly hard. How do you allow users to search when you have no server functions and no database?
With JavaScript!
We've recently added Search to the TrackJS Documentation site, built using the Jekyll website generator and hosted on GitHub Pages. GitHub wasn't too keen on letting us run search functions on their servers, so we had to find another way to run full-text search on our documentation.
Our documentation is about 43,000 words spread across 39 pages. That's actually not much data as it turns out--only 35 kilobytes when serialized for search. That's smaller than some JavaScript libraries.
Building the Search Index
We found a project called Lunr.js, which is a lightweight full-text search engine inspired by solr. Plus, it's only 8.4 kilobytes, so we can easily run it client-side.
Lunr takes an array of keyed objects to build its index, so we need to get our data to the client in the right shape. We can serialize our data for search using Jekyll's native filters like: xml_escape, strip_html, and jsonify. We use these to build out an object with other important page context, like page title and url. This all comes together on a search.html page.
<ol id="search-results"></ol>
<script>
window.pages = {
{% for page in site.pages %}
"{{ page.url | slugify }}": {
"title": "{{ page.title | xml_escape }}",
"content": {{ page.content | markdownify | strip_newlines | strip_html | jsonify }},
"url": "{{ site.url | append: page.url | xml_escape }}",
"path": "{{ page.url | xml_escape }}"
}{% unless forloop.last %},{% endunless %}
{% endfor %}
};
</script>
<script src="/lunr-2.3.5.min.js"></script>
<script src="/search.js"></script>
The above HTML fragment is the basic structure of the search page. It creates a JavaScript global variable, pages, and uses Jekyll data to build out the values from site content pages.
Now we need to index our serialized page data with lunr. We'll handle our custom search logic in a separate search.js script.
var searchIndex = lunr(function() {
this.ref("id");
this.field("title", { boost: 10 });
this.field("content");
for (var key in window.pages) {
this.add({
"id": key,
"title": pages[key].title,
"content": pages[key].content
});
}
});
We build out our new searchIndex by telling lunr about the shape of our data. We can even boost the importance of fields when searching, like increasing the importance of matches in page title over page content. Then, we loop over all our global pages and add them to the index.
Now, we have all our documentation page data in a lunr search engine loaded on the client and ready for a search anytime the user visits the /search page.
Running a Search
We need to get the search query from the user to run a search. I want the user to be able to start a search from anywhere in the documentation--not just the search page. We don't need anything fancy for this, we can use an old-school HTML form with a GET action to the search page.
<form action="/search/" method="GET">
<input required type="search" name="q" />
<button type="submit">Search</button>
</form>
When the user enters their search query, it will bring them to the search page with their search in the q querystring. We can pick this up with some more JavaScript in our search.js and run the search against our index with it.
function getQueryVariable(variable) {
var query = window.location.search.substring(1);
var vars = query.split("&");
for (var i = 0; i < vars.length; i++) {
var pair = vars[i].split("=");
if (pair[0] === variable) {
return decodeURIComponent(pair[1].replace(/\+/g, "%20"));
}
}
}
var searchTerm = getQueryVariable("q");
// creation of searchIndex from earlier example
var results = searchIndex.search(searchTerm);
var resultPages = results.map(function (match) {
return pages[match.ref];
});
The results we get back from lunr don't have all the information we want, so we map the results back over our original pages object to get the full Jekyll page information. Now, we have an array of page results for the user's search that we can render onto the page.
Rendering the Results
Just like any other client-side rendering task, we need to inject our result values into an HTML snippet and place it into the DOM. We don't use any JavaScript rendering framework on the TrackJS documentation site, so we'll do this with plain-old JavaScript.
// resultPages from previous example
resultsString = "";
resultPages.forEach(function (r) {
resultsString += "<li>";
resultsString += "<a class='result' href='" + r.url + "?q=" + searchTerm + "'><h3>" + r.title + "</h3></a>";
resultsString += "<div class='snippet'>" + r.content.substring(0, 200) + "</div>";
resultsString += "</li>"
});
document.querySelector("#search-results").innerHTML = resultsString;
If you want to put other page properties into the results, like tags, you'd need to add them to your serializer so you have them in resultsPages.
With some thought on design, and some CSS elbow-grease, it turns out pretty useful!
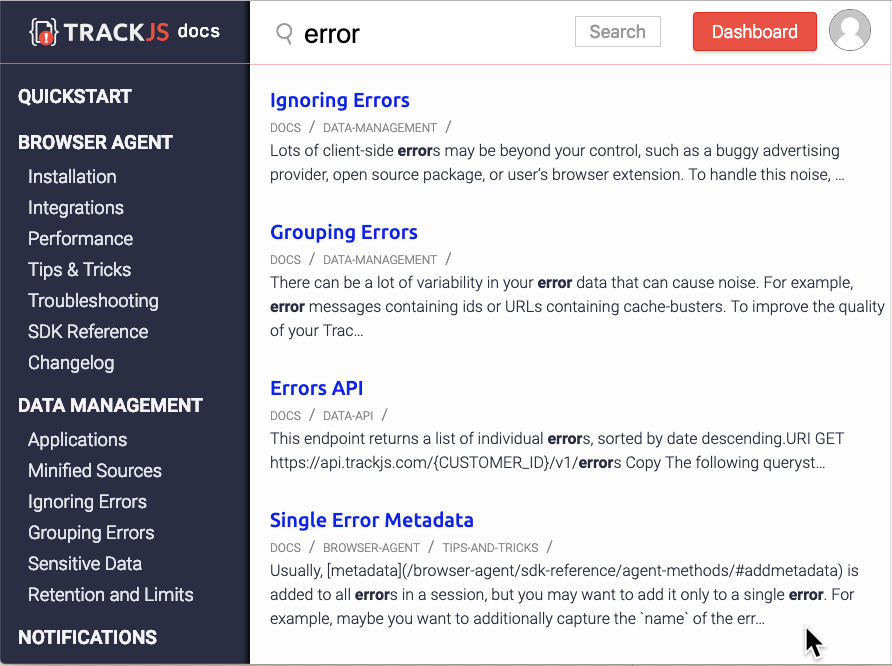
I'm pretty happy with how it turned out. You can see it in action and checkout the final polished code on the TrackJS Documentation Page. Of course, with all that JavaScript, you'll need to watch it for bugs. TrackJS can help with that, grab your free trial of the best error monitoring service available today, and make sure your JavaScript keeps working great.
Ready for even better search? Check out "Site Search with JavaScript Part 2", over on the TrackJS Blog. We expand on this example and improve the search result snippets to show better context of the search term, and dynamic highlighting of the search term in pages. It really improves the user experience.



About Todd Gardner
Todd Gardner is a software entrepreneur and developer who has built multiple profitable products. He pushes for simple tools, maintainable software, and balancing complexity with risk. He is the cofounder of TrackJS and Request Metrics, where he helps thousands of developers build faster and more reliable websites. He also produces the PubConf software comedy show.