How to Detect Text in Images
Images are a great way to communicate without text but oftentimes images are used/abused to spread text within social media and advertisements. Text in images also presents an accessibility issue. The truth is that it's important, for any number of reasons, to be able to detect text in image files. The amazing open source tool that makes detecting text in images possible is tesseract OCR!
I recommend using Homebrew to install tesseract:
brew install tesseract
To run tesseract to read text from an image, you can run the following from command line:
tesseract ~/Downloads/MyImage.png ~/Downloads/MyImage.txt -l eng
The command above extracts detected text in the English language (-l eng) into a text file (MyImage.txt). The process is very quick and there are dozens of supported languages.
Let's look at the following example:
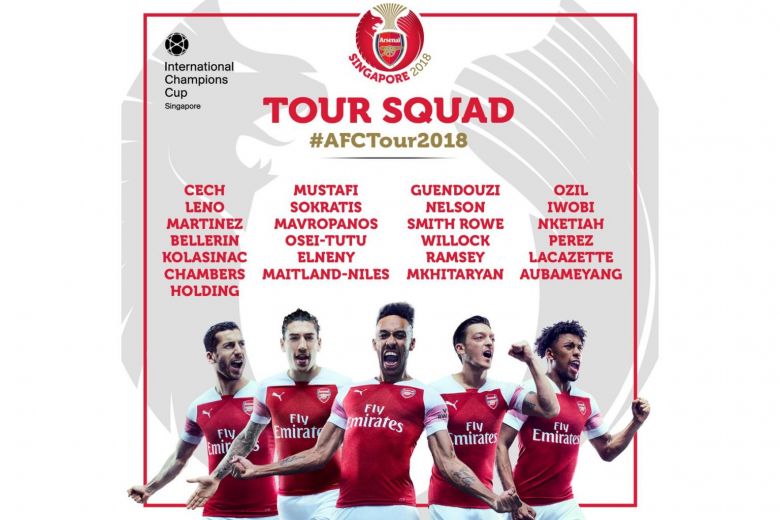
The following text is detected:
International ‘Champions Cup ~- TOUR SQUAD #AFCTour2018 CECH MUSTAFI GUENDOUZI oziL LENO SOKRATIS NELSON IWOBI MARTINEZ MAVROPANOS SMITHROWE = NKETIAH BELLERIN OSEI-TUTU WILLOCK PEREZ KOLASINAC ELNENY RAMSEY LACAZETTE CHAMBERS MAITLAND-NILES MKHITARYAN AUBAMEYANG HOLDING
There are a number of utilities in different programming languages that plug into tesseract's functionality, but it's important to know the underlying tool! tesseract is an unbelievable tool that you should take advantage of if you need an open source utility for detecting text in an image!