How to Reverse Engineer OS X and iOS Software
The question of why we need to employ reverse engineering is an easy one to answer. When there is an executable, but no access to the source code, yet you still need to understand the inner workings of this particular software, you apply reverse engineering to it. Business situations where reverse engineering will be useful are many and they are very varied:
- Researching complex software problem
- Improving compatibility with closed solutions and formats
- Improving interaction with a particular platform
- Making maintenance of legacy code easier
There are many other cases where you need to reverse engineer software. In this article we will look at how to reverse engineer iOS app, as well as OS X software, and try to give you some practical advice on what you need to know and what tools you need to have.
Understanding binary structure
When reverse engineering a binary, you should now where executable code is situated inside it. Knowing binary structure is paramount in successfully learning how to reverse engineer software.
Executable binary format. Mach-O format of executable are very commonly used among the systems based on Mach kernel. It can be contained in either 'thin' binaries or 'fat' binaries. While thin binary has a sole Mach-O executable, fat binary can have many of them at once. Fat binaries are usually employed to combine executable code in a single file.
Header. The most important part of iOS or OS X executable is the header. Header is the first thing that loader reads when loading image. Thus, header is something that every binary starts with. Header always begins with a magic number that serves identification purposes. Different types of binaries employ different headers, with thin binaries using mach header and fat binaries using their own fat header, used to describe where all the mach headers in the binary are located.
The fat header starts with the 0xcafebabe magic number and contains information about every executable that resides in the binary file: CPU type and subtype, file offset and align values.
cyber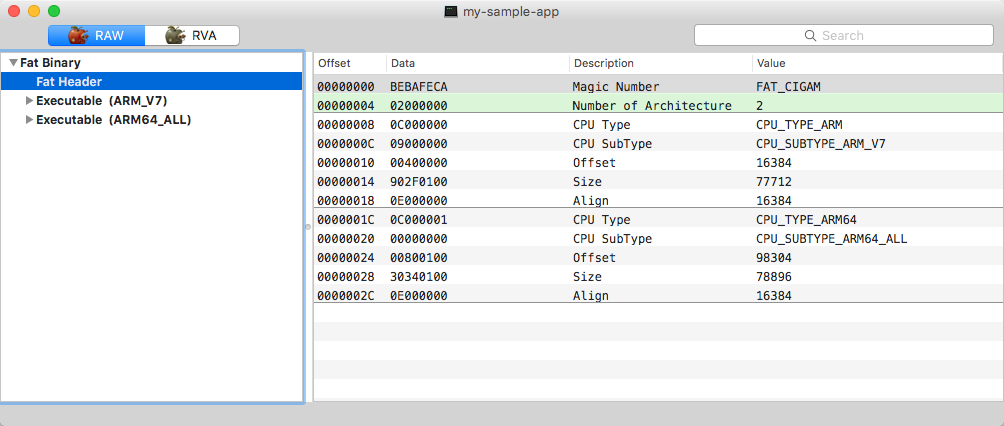 Fat Header of 'fat' executable
Fat Header of 'fat' executable
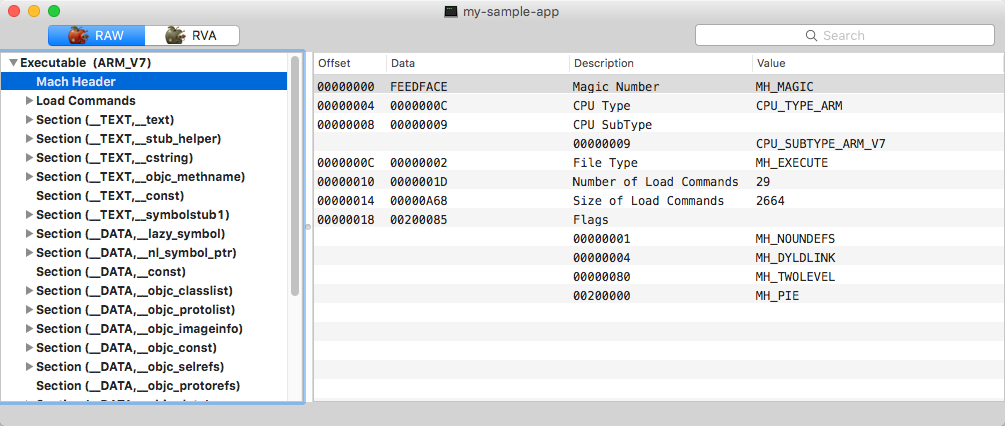 Mach Header of executable in 'thin' binary
Mach Header of executable in 'thin' binary
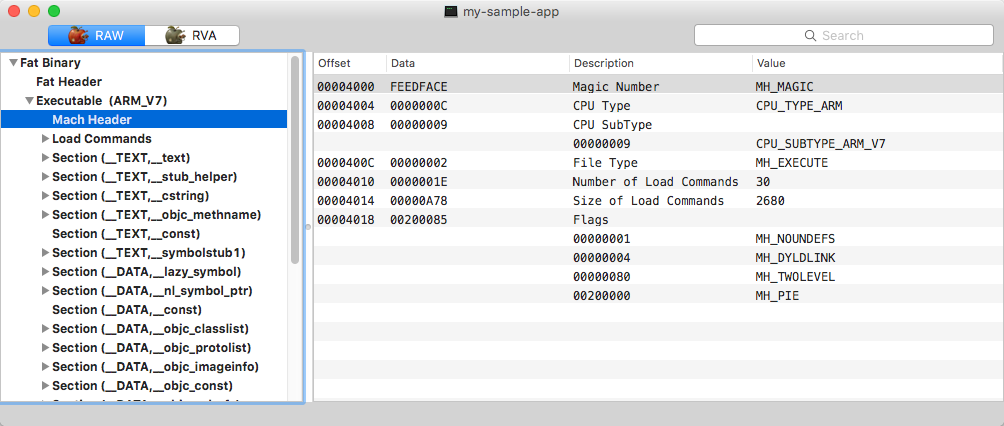 Mach Header of the first executable in 'fat' binary
Mach Header of the first executable in 'fat' binary
Each mach header starts with the 0xfeedface magic number and contains general information about the executable, such as target CPU type, subtype, loading options and load commands count and offset. Load commands provide the crucial information for loading image:
- Sections and segments of executable, as well as their mapping to virtual memory
- Paths of linked dynamic libraries
- Symbol tables location
- Code signature
Segments. Large parts of executable that are mapped to a certain virtual address space by the loader are called segments. Segments are divided by sections, each storing a certain type of information.
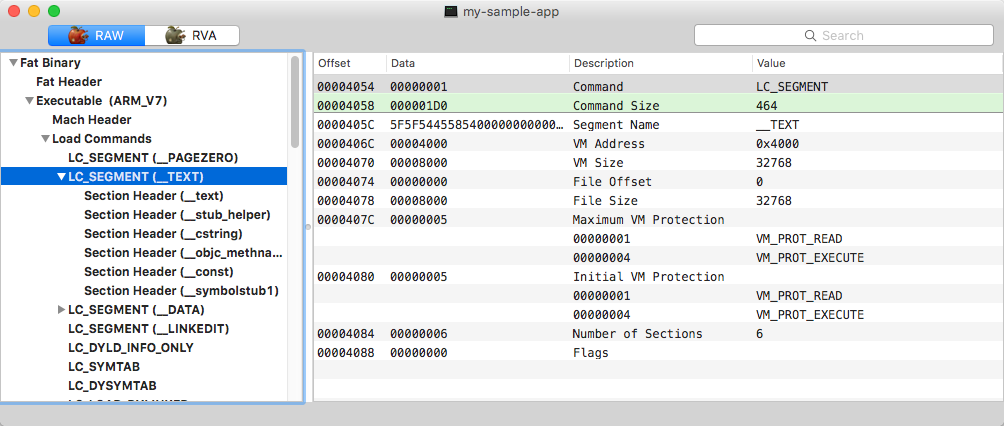 The 'TEXT' segment
The 'TEXT' segment
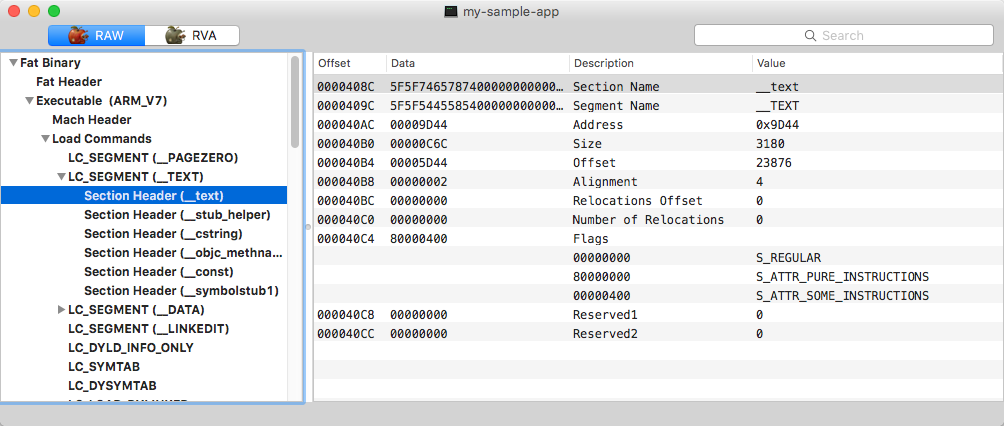 Section 'text' of the 'TEXT' segment
Section 'text' of the 'TEXT' segment
All segments are byte streams. They start with command type and size, which may vary from one command to another.
Load Commands. Load commands describe each dynamic library dependency and include paths to corresponding binary files. Moreover, load commands also include locations of import and stub tables, symbol tables, as well as table that contains information for dynamic loader.
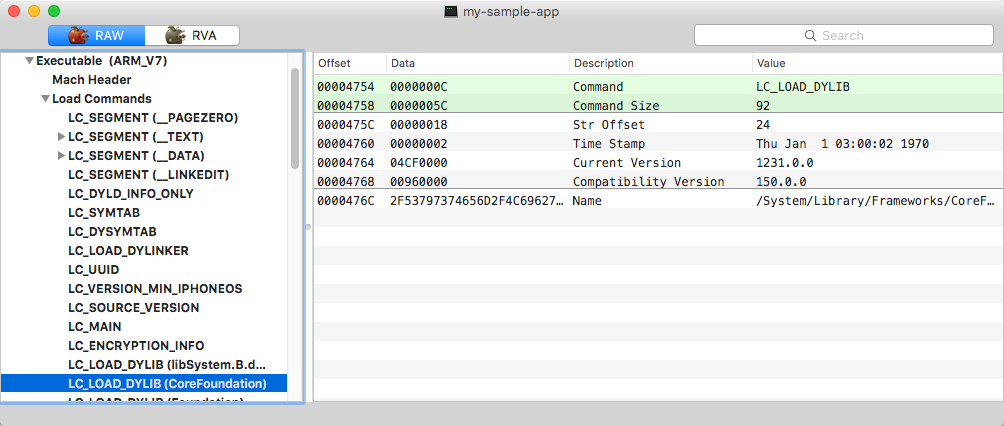 Load command for loading CoreFoundation binary
Load command for loading CoreFoundation binary
Symbol tables. All currently used symbols, both locally and externally defined, as well as stubs, generated via external calls executed via import table, are contained in the main symbol table.
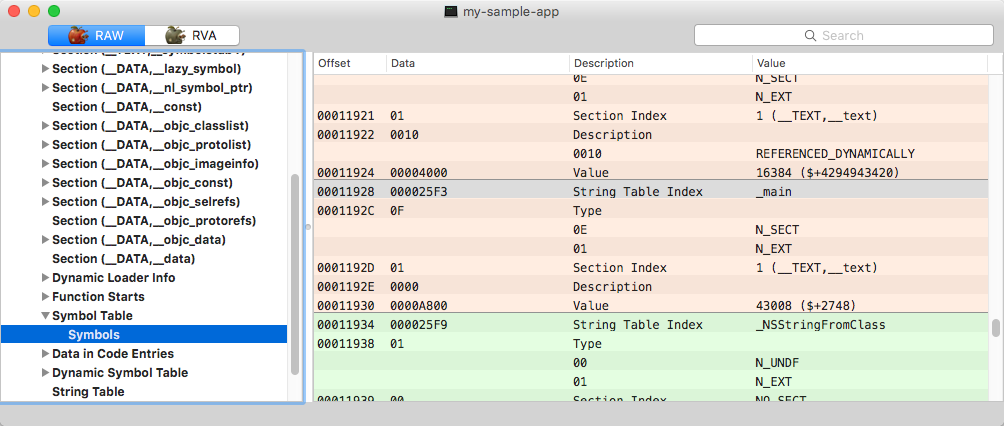 Symbol table
Symbol table
Table is divided depending on whether the symbol is local, external, or debug. Each entry represents a certain part of the code via specifying name offset in the string table, ordinal section, type, or any other specific information.
Names of symbols from the main symbol table are contained in a separate string table. Another dynamic symbol table links each import table entry to the corresponding symbol. There is also a separate table with necessary data employed by dynamic loader for each external symbol.
Code signature. While code signature is freely available via open-source, just as in many other open-source projects, it is pretty badly documented. It can be viewed and managed by the codesign tool that allows to work with different signature parts. The location of code signature within the binary file is provided by the corresponding load command.
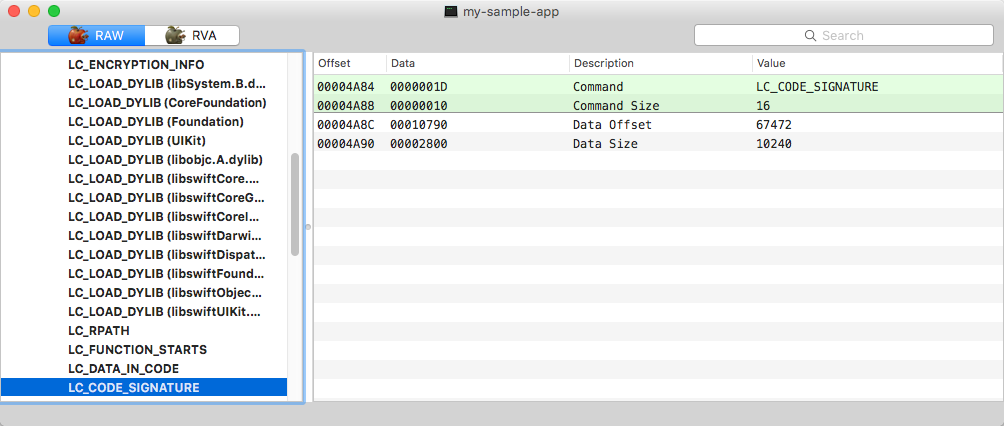 Load command for Code Signature
Load command for Code Signature
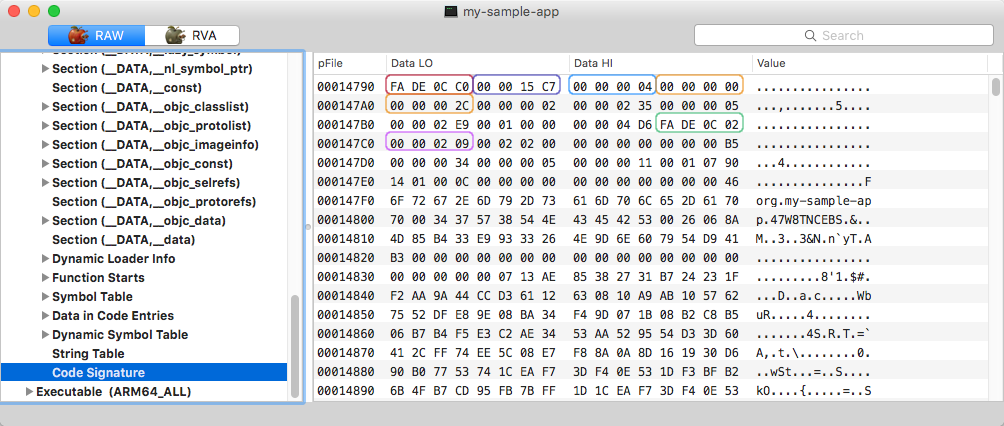 Code signature bytestream
Code signature bytestream
Code signature itself contains its own header, which starts with the byte sequence:
- Magic number (0xfade0cc0)
- Code signature blob size
- Slots count
The header is followed by the signature slot indexing byte-pair, where the first byte is a type and the second is a signature slot offset. Offset points to the beginning of a particular slot.
Each slot starts with the sequence of two bytes:
- Magic number (0xfade0cc2)
- Slot size
Code signature slots are intended to contain a number of important things such as:
- Code directory
- Signature requirements
- Sealed resource description
- Entitlements
- Code signature
Table of hashes, as well as hash algorithm, code page size and table size are all contained within code directory. Table is divided into positive part, that has hashes of pages of executable code, and negative part, that optionally includes hashes of different code signature parts, as well as hash of info.plist.
Entitlements, resources and code signing requirements are simple bytestreams of particular files situated inside the bundle.
Code signature slot always contains encrypted code directory that uses CMS format.
What else you need to know
Architecture. Nowadays, every desktop device employs x86-64 CPUs, while mobile devices usually use some variation of ARMv7 or ARMv8 architecture. Knowing instruction sets of a particular CPU architecture is very important for successful algorithm reverse-engineering. It is also very beneficial to know calling conventions and various ARM specifics, such as thumb mode or opcodes format.
Caches. In modern software, a single file called shared cache is used to merge all system frameworks and dylibs. It is located at /System/Library/Caches/com.apple.dyld/.
Reverse engineering tools
Mac provides some tools for iOS and OS X reverse engineering out of the box. Tools in question include:
- lldb – powerful debugger
- otool – console tool that can be used to view the content of Mach-O executables
- nm – allows to view names and symbols contained inside Mach-O executables
- codesign – provides detailed information about code signatures
Additionally, many third-party tools and utilities are also available, that can help you with OS X and iOS reverse engineering process. Examples of such tools include:
- Interactive DisAssembler (IDA) – one of the most useful and important tools for conducting complex and detailed researches on executables.
- MachOView – in terms of functionality this freeware tool is similar to otool and nm (in that it allows to view Mach-O files structure), but it presents information in a much more easy and intuitive way due to having a GUI. Main drawback of MachOView is that it is quite unstable.
- Class-dump – tool, that allows to dump class declarations into normal headers from an executable one.
- Hopper – great interactive shareware tool for iOS and OS X software reverse engineering.
Conclusion
Learning how to reverse engineer OS X software or iOS apps can be quite a challenge. It requires both advanced knowledge and experience with programming in order to understand the structure of the software and the intent of the person writing it. However, by going at it and sticking to it, anybody can learn OS X and iOS software reverse engineering, and the skills, gained in the process will greatly benefit you when it comes to improving your own software.



About Dennis Turpitka
Dennis Turpitka, CEO of the Apriorit, is an expert within Digital Security solution business design and development, Virtualization and Cloud Computing R&D projects, establishment and management of Software Research direction. Successful entrepreneur, who organized several security start-ups.