Modernization of Reactivity
Reactive programming has taken JavaScript by storm over the last decade, and for good reason; front-end development greatly benefits from the simplicity of writing user interface code that "reacts" to data changes, eliminating substantial error-prone imperative code tasked with updating UIs. However, while the popularity has increased, tools and techniques have not always kept up with modern browser functionality, web APIs, language capabilities, and optimal algorithms for performance, scalability, syntactic ease, and long-term stability. In this post, let's look at some of the newer technologies, techniques, and capabilities that are now available, and demonstrate these in the context of a new library, Alkali.
The techniques we will look at include queued rendering, pull-based granular reactivity, reactive ES6 generators and expressions, reactive native web components, and reversible directional flow. These approaches are more than just fad-driven progamming, they are the result of adopted browser technologies and incremental research and development that produce better performance, cleaner code, inter-operability with future components, and improved encapsulation.  Again, we will be looking at Alkali for examples of resulting simple succinct declarative style (you can jump ahead see the Alkali todo-mvc application for a more complete example) with standard native element architecture and perhaps the most important feature we can build: fast performance with minimal resource consumption. These modern techniques really do yield substantial performance, efficiency, and scalability benefits. And with the constant churn of new libraries, the most prescient and stable architecture is building directly on the standards-based browser element/component API.
Again, we will be looking at Alkali for examples of resulting simple succinct declarative style (you can jump ahead see the Alkali todo-mvc application for a more complete example) with standard native element architecture and perhaps the most important feature we can build: fast performance with minimal resource consumption. These modern techniques really do yield substantial performance, efficiency, and scalability benefits. And with the constant churn of new libraries, the most prescient and stable architecture is building directly on the standards-based browser element/component API.
Push-Pull Reactivitiy
A key to scaling reactive programming is the architectural flow of data. A naive approach to reactivity is to use a simple observable or listener pattern to push every update through a stream with every evaluation to every listener. This quickly can results in excessive computations in any type of multiple-step state update that leads to unnecessarily repeated intermediate evaluations. A more scalable approach is to use "pull"-based approach, where any computed data is calculated lazily when downstream observer requests or "pulls" the latest value. Observers can request data using de-bouncing or queuing after being notified that dependent data has changed.
A pull-based approach can also be used in conjunction with caching. As data is computed, results can be cached, and notifications of upstream changes can be used to invalidate downstream caches to ensure freshness. This cache and invalidation scheme of pull-based reactivity follows the same design architecture as REST, the scalable design of the web, as well as the architecture of modern browser rendering processes.
There are, however, situations where it is preferable to have certain events be "pushed" where they incrementally update the current state. This is particularly useful for progressive updates to collection where items can be added, removed, or updated without propagating an entire collection state. The most broadly performant approach is a hybrid: data flow is primarily is pulled from the observer, but incremental updates can be pushed through live data flows as an optimization.
Queued Rendering
The key to leveraging pull-based reactive dependencies for efficiency in reactive applications is ensuring that rendering execution is minimized. Frequently, multiple parts of an application may update the state of the application, which can easily lead to thrashing and inefficiency if rendering is synchronously executed immediately on any state change. By queuing the rendering we can ensure that even when multiple state changes occur, rendering is minimized.
Queuing actions or de-bouncing is a relatively common and well-known technique. However, for optimal queuing of rendering, browsers actually provide an excellent alternative to generic de-bouncing functions. Due to its name, requestAnimationFrame is often relegated to animation libraries, but this modern API is actually perfect for queuing up rendering of state changes. requestAnimationFrame is a macro event task, so any micro tasks, like promise resolutions will be allowed to complete first. It also allows browsers to determine precisely the best timing to render new changes, taking into consideration the last rendering, tab/browser visibility, current load, etc. The callback can be executed without delay (usually sub-millisecond) in resting visible state, at an appropriate frame rate in sequential rendering situations, and even completely deferred when a page/tab is hidden. In fact, by queuing state changes with requestAnimationFrame, and rendering them as needed for visual update, we are actually following the same optimized rendering flow, precise timing, and sequence/path that modern browsers themselves use. This approach ensures that we are working in a complementary way with browsers to render efficiently and timely, without incurring extra layouts or repaints.
This can be thought of as a two-phrase rendering approach. The first phase is a response to event handlers where we update canonical data sources, which triggers the invalidation of an derived data or components that rely on that data. All invalidated UI components are queued for rendering. The second phase is the rendering phase where components retrieve their necessary data and render it.
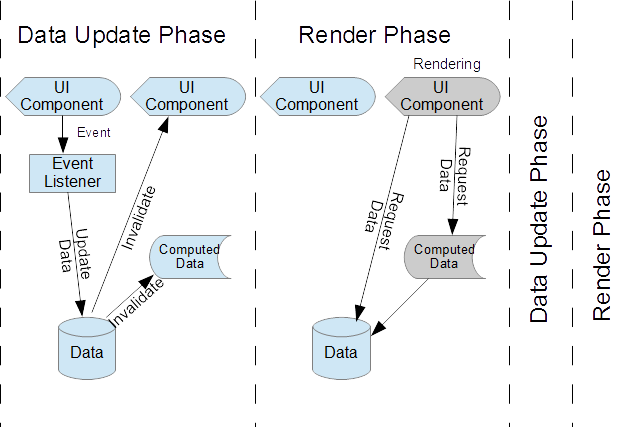
Alkali leverages this rendered queuing through its renderer objects, that connect reactive data inputs (called "variables" in alkali) to an element, and then queues all state changes for re-rendering through the requestAnimationFrame mechanism. This means any data bindings are connected to queued renderings. This can demonstrated by creating a reactive value with the Variable constructor, and connecting this to an element (here we create a <div>). Let's look at some example code:
import { Variable, Div } from 'alkali'
// create a variable
var greeting = new Variable('Hello')
// create div with the contents connected to the variable
body.appendChild(new Div(greeting)) // note that this is a standard div element
// now updates to the variable will be reflected in the div
greeting.put('Hi')
// this rendering mechanism will be queue the update to the div
greeting.put('Hi again')
This connection will automatically update the div using the requestAnimationFrame mechanism anytime the state changes, and multiple updates will not cause multiple renderings, only the last state will be rendered.
Granular Reactivity
Pure functional reactivity programming allows individual signals or variables to be used and propagated through a system. However, in the interest of maintaining the familiarity of imperative programming, diff-based reactive frameworks like ReactJS, that use a virtual DOM, have become very popular. These allow applications to be written in the same way we might write an application with imperative code. When any application state changes, components simply re-render, and once completed the component output is diffed with previous output to determine the changes. Rather than explicit data flows that generate specific changes to the rendered UI, diffing compares the output of re-execution with previous states.
While this can produce a very familiar and convenient paradigm for coding, it comes at a significant cost in terms of memory and performance. Diffing reactivity requires a full copy of rendered output and complex diffing algorithms to determine differences and mitigate excessive DOM rewriting. This virtual DOM typically requires 2 to 3 times the memory usage of a DOM alone, and the diffing algorithms add similar overhead compared to direct DOM changes.
On the other hand, true functional reactive programming explicitly defines the "variables" or values that can change, and the continuous output of these values as they change. This does not require any additional overhead or diffing algorithms, as the output is directly specified by the relationships defined in the code.
Debuggability also benefits from granular functional reactive code flow. Debugging imperative programming involves recreating conditions and stepping through blocks of code, requiring complex reasoning to evaluate how state changes (and how it is going wrong). Functional reactive flows can be statically inspected, where we always have full visibility to the graph of individual dependent inputs that correspond to UI output, at any point in time.
Again, using true functionally reactive programming techniques is not merely an esoteric or pedantic computer science endeavor, but an approach with meaningful and significant benefits to the scalability, speed, responsiveness, ease of debugging, and flow of your application.
Canonical and Reversible Data
The explicit flow of granular reactivity also makes it possible to reverse data flows to achieve two-way bindings, such that downstream data consumers, like input elements, can request upstream data changes without extra configuration, wiring, or imperative logic. This makes it extremely easy to build and bind the input controls in forms.
An important principle of reactivity is "single source of truth", where there is an explicit distinction between canonical data sources and derived data. The reactive data can be described as a directed graph of data. This is vital for coherent data management. Synchronizing multiple data states without a clear direction of source and derived data, makes data management confusing and leads to various statement management issues.
Single-directional flow with centralized data changes, associated with diffing reactivity, is one form of a proper directed graph of data. Unfortunately, single-directional flow ultimately means that data consumers must may be manually wired to source data, which typically violates the principle of locality and gradually degrades encapsulation, resulting in increasingly entangled state handling between otherwise separable and independent components, and more complicated form development.
However, a directed graph with canonical source does not necessarily dictate data can only be communicated one way through the graph. With granular reactivity, we can support reversible flow. With reversibility, directionality can still be preserved by defining downstream data changes as a notification of a change that has already been occurred or initiated (in the past), while in contrast, an upstream data change is defined as a request for a change to be initiated (in the future, and revocable). A request for a change to derived data can still be made as long as it has a reverse transform to propagate the request to a source (reversible data traversals or transforms are often called a "lens" in functional terminology). The canonical data change still happens at the data source, even if initiated/requested by a downstream consumer. With this clear distinction of flow, the directed graph of canonical sources and derived data is still preserved, maintaining consistency in state, while still allowing encapsulation in interaction with individual data entities, regardless of whether or not they are derived. In practical terms, this simplifies developing user input and form management, and encourages encapsulation of input components.
Modern DOM Extensions ("Web Components")
Foresight is critical for the long-term development and maintainability, and this is challenging in the JavaScript ecosystem where numerous technologies are constantly emerging. What new framework will be exciting three years from now? If the past is any indicator, this is very difficult to predict. How do we develop with this type of churn? The most reliable approach is to minimize our reliance on library specific APIs, and maximize our reliance on standard browser APIs and architecture. And with the emerging component APIs and functionality (aka "web components") this is becoming much more feasible.
Well-defined reactive structures should not dictate a specific component architecture, and the flexibility to use native or third-party components maximizes possibilities for future development. However, while we can and should minimize coupling, some level of integration can be useful. In particular, being able to directly use variables as inputs or properties is certainly more convenient than having to create bindings after the fact. And, integration with element/component life-cycle, and notification of when elements are removed or detached, can facilitate automatic cleanup of dependencies and listening mechanisms, to prevent memory leaks, minimize resource consumption, and simplify component usage.
Again, modern browsers have made this type of integration with native elements completely feasible. It is now possible to extend from existing HTML prototypes for real DOM-based custom classes, with reactive variable-aware constructors, and the MutationObserver interface (and potential future web component callbacks) give us the ability to monitor when elements are detached (and attached). The getter/setter functionality introduced in ES5 allows us to properly extend and reproduce native element style properties as well.
Alkali defines a set of DOM constructors/classes with exactly this functionality. These classes are minimal extensions to native DOM classes with constructors with arguments that support variable inputs that drive properties, and automated cleanup of variables. In conjunction with lazy/pull-based reactivity, this means elements reactively display data while visible, and once detached, will no longer trigger any evaluations through its dependency of inputs. This results in an element creation and extension with automated self-cleanup of listeners. For example:
let greetingDiv = new Div(greeting) body.appendChild(greetingDiv) // a binding will be created that listens for changes to greeting ... body.removeChild(greetingDiv) // binding/listener of greeting will be cleaned up
Reactive Generators
Not only do web APIs provide important improvements in our approach to reactivity, the ECMAScript language itself has exciting new features that can be used to improve syntax and ease of writing reactive code. One of the most powerful new features is generators, which provide an elegant and intuitive syntax for interactive code flow. Perhaps the biggest inconvenience of working with reactive data in JavaScript is the frequent need for callback functions for handling state changes. However, ECMAScript's new generator functions provides the ability to pause, resume, and restart a function such that the function can utilize reactive data inputs with standard sequential syntax, pausing and resuming for any asynchronous inputs. Generator controllers can also auto-subscribe to dependent inputs, and re-execute the function when inputs change. This control of function execution that is made possible by generators can be leveraged to yield (pun intended!) an intuitive and easy-to-follow syntax for complex combinations of variable inputs.
Generators have been anticipated for how they eliminate callbacks with promises, and enable an intuitive sequential syntax. But generators can be taken even further to not only pause and resume for asynchronous input, but restart when any input value changes. This can be accomplished by using the yield operator in front of any variable input, which allows the coordinating code to listen to the variable for changes, and return the current value of the variable to the yield expression when it is available.
Let's take a look at how this is accomplished. In Alkali, generator functions can be used as a transform for input variables, to create a reactive function that outputs a new composite variable with the react. The react function acts as a generator controller to handle reactive variables. Let's break down an example of this:
let a = new Variable(2)
let aTimesTwo = react(function*() {
return 2 * yield a
})
The react controller handles executing the provided generator. A generator function returns an iterator that is used to interact with the generator, and react starts the iterator. The generator will execute until it evaluates a yield operator. Here, the code will immediately encounter the yield operator, and return control to the react function with the value provided to the yield operator returned from the iterator. In this case, the a variable will be returned to the react function. This gives the react function the opportunity to do several things.
First, it can subscribe or listen to the provided reactive variable (if it is one), so it can react to any changes by re-executing. Second, it can get the current state or value of the reactive variable, so it can return that back as the result of yield expression, when resuming. Finally, before returning control, react function can check if the reactive variable is asynchronous, holding a promise to value, and waiting for the promise to resolve before resuming execution, if necessary. Once the current state is retrieved, the generator function can be resumed with value of 2 returned from the yield a expression. If more yield expressions are encountered they will be sequentially resolved in the same way. In this case, the generator will then return a value of 4, which will end the generator sequence (until a changes and it is re-executed).
With the alkali react function, this execution is encapsulated in another composite reactive variable, and any variable changes will not trigger re-execution until downstream data accesses or requests it.
Alkali generator functions can also be used directly in element constructors to define a rendering function that will automatically re-execute whenever an input value changes. In either case, we then use the yield in front of any variable. For example:
import { Div, Variable } from 'alkali'
let a = new Variable(2)
let b = new Variable(4)
new Div({
*render() {
this.textContent = Math.max(yield a, yield b)
}
})
This creates a <div> with a text content of 4 (the maximum of the two input values). We could update either variable, and it will re-execute:
a.put(5)
The <div> would now be updated to have a content of 5.
Generators are not universally available in all browsers (not in IE and Safari), but generators can be transpiled and emulated (with Babel or other tools).
Properties and Proxies
Reactively binding to properties of object is an important aspect of reactivity. But to encapsulate a property with notification of changes, requires more than just the current property value returned by standard property access. Consequently, reactive property bindings or variables can require verbose syntax.
However, another exciting new feature in ECMAScript is proxies, which allows us to define an object that can intercept all property access and modifications with custom functionality. This is powerful functionality, that can be used to return reactive property variables through ordinary property access, enabling convenient, idiomatic syntax with reactive objects.
Unfortunately proxies are not so easily emulated through code compilers like Babel. Emulating proxies would require not only transpiling the proxy constructor itself, but any code that might access the proxy, so emulation without native language support would either be incomplete or unreasonably slow and bloated due to the massive transpilation required of every property access in an app. But more targeted transpilation of reactive code is possible. Let's look at that.
Reactive Expressions
While the EcmaScript is constantly advancing, tools like Babel and its plugin capability, give us tremendous opportunities for creating new compiled language features. And while generators are awesome for creating a function with series of steps that can execute asynchronously and re-execute reactively, with a Babel plugin, code can be transformed to actually create fully reactive data flows, with property bindings, using ECMAScript syntax. This goes further than simply re-execution, but the output of expressions can be defined in relation to inputs such that reversible operators, reactive properties, and reactive assignments can be generated using simple, idiomatic expressions.
A separate project houses an alkali-based babel plugin for transforming reactive expressions. With this we can write a normal expression as an argument to a react call/operator:
let aTimes2 = react(a * 2)
This aTimes2 will be bound to the multiplication of the input variable. If we change the value of a (using a.put()), aTimes2 will auto-update. But because this is actually two-way binding through a well-defined operator, the data is reversible as well. We can assign a new value to aTimes2 of 10, then a will be updated to a value of 5.
As mentioned, proxies are nearly impossible to emulate across a whole code-base, but within our reactive expressions, it is very reasonable to compile property syntax to handle properties as reactive variables. Furthermore, other operators can be transpiled to reversible transformations of variables. For example, we could write complex combinations with fully reactive, language-level code:
let obj, foo
react(
obj = {foo: 10}, // we can create new reactive objects
foo = obj.foo, // get a reactive property
aTimes2 = foo // assign it to aTimes2 (binding to the expression above)
obj.foo = 20 // update the object (will reactively propagate through foo, aTimes2, and to a)
)
a.valueOf() // -> 10
Modernizing
Web development is an exciting world of constant change and progress. And reactivity is a powerful programming concept for sound architecture of advance applications. Reactivity can and should grow to use the latest new technologies and capabilities of the modern browser and its language and APIs. Together they can yield another step forward in web development. I am excited for the possibilities, and hope these ideas can advance the ways we can leverage the future with new tools.
Alkali has been developed as our engineering team, at Doctor Evidence, has been working to build interactive and responsive tools for exploring, querying, and analyzing large data sets of clinical medical studies. It has been a fascinating challenge to maintain a smooth and interactive UI with complex and vast data, and many of these approaches have been very useful for us, as we adopt newer browser technologies in developing our web software. If nothing else, hopefully Alkali can serve as an example to inspire more steps forward in web development.



About Kris Zyp
Kris Zyp has been involved in the JavaScript web community for many years, helping define specifications including JSON Schema, Promises/A, and AMD and build and contribute to open source projects including Dojo, Persevere, and others. Kris lives with his wife and two kids in Utah, where they love to ski, hike, bike, and climb. He works for Doctor Evidence building web software for aggregation and statistical analysis of clinical medical studies.




This is awesome, both the framework and the article. Already playing around with Alkali and appreciating the simplicity and use of pure functions.
Questions:
(1) Server side rendering?
(2) Plain routes without hash
Are these doable or planned?
Steven,
Thanks for the comments, I don’t have any immediate plans for these, but I think they are doable.
> Server side rendering?
There are several levels of this that are possible. First, you could simply use Alkali’s element constructors to generate a headless DOM on the server, and send the HTML to the browser. This probably could already be pretty easily done with an existing Node DOM library. This could be improved with maybe an optimized pseudo-DOM for Alkali. However, it might not be that interesting on it’s own, since there isn’t really any reactivity to it. It may be useful for creating a static copy of site, before attaching live reactive variables to it on the client side.
However, you could take that further, and cache the generated HTML, and then use reactive variables as way to invalidate/regenerate the cache, using reactivity for a highly efficient caching system. This would pretty cool, although it would not do anything for live updates to the browser.
You could go further and create some type of system where reactive DOM on the server could be updated and send live updates of HTML changes to the browser. This would be pretty complicated though, and it seems like most frameworks that do this type of server-based client updating have fallen out of favor.
> Plain routes without hash
I haven’t done this type of thing yet, although I certainly think it would be pretty cool to have a router with consumable variable(s) that represent the current route (you may have noticed that the TodoMVC has an extremely simple hash-based router setup). I think it could be done as a separate component though; I have been primarily focused on core functionality.
Very instructive and well written.
Untill now I have been playing with Polymer, and kind of liked their Webcomponents / Polyfill and PRPL pattern…But I’ll definitely give Alkali a close look ;)
Interesting and informative write-up Kris!
I did notice in the performance metrics that the todomvc performance comparison is using some very old versions of Angular, Ember, and React, so I’d be curious to see what the numbers look like with more recent versions. I would also be curious to see how some of the smaller vdom implementations perform (e.g. Maquette+Dojo 2’s todomvc example app).
Dylan,
I did my best to upgrade these libraries, but I couldn’t seem to get React to work past 0.10.0 (wouldn’t render everything), and I didn’t try switching to Angular 2, just upgrading to the latest v1:
https://github.com/kriszyp/todomvc-perf-comparison/commit/b736e0daf9e579a7bbb57e164b4f77f6c6920d4e
Those libraries improved a little bit, but it wasn’t dramatic.
It would be interesting to try the Dojo 2 example, do you have a todomvc-perf test harness for it?
Hi Kris,
Thanks… perhaps for our beta, I’ll reach out when we’re closer to that!
-Dylan
Clean, succinct overview and justification. I appreciate the solution model, as I have been looking at Cycles, Motorcycle, and other reactive frameworks. Alkali as a project has, it seems to me, a tight coupling of the infrastructure for the reactive variables with the DOM generation elements. I think the reactive Variables are useful outside of Browser settings (in NodeJS code, perhaps deployed in containers). Cycle separated the browser aspect from the underlying (relied-upon) reactive streams (xstream). What are your thoughts about separating the reactive Variables from the DOM aspects to make two code bases?
Stuart,
Yes, definitely, Alkali variables are absolutely intended to be used without any dependency on the DOM parts of the Alkali, and can certainly be used on Node (the Travis CI tests run on Node, in fact). It is true that the DOM constructor module (alkali/Element) is in the same repo/project, and I guess these could be separated, but the variable module (alkali/Variable) is distinct, has no dependencies whatsoever on the element generation, and even the root module can be loaded on Node and used there.
Nice article!
Checked out Alkali after reading this and loved it.
Made a simple HTML to Alkali.js convertion tool in case others want to use it: https://sergiocrisostomo.github.io/html-to-alkali/
The chart above tells me something sad… That Vue.js is either skipped, or has a tremendously small usage base.
I agree, Vue.js should not be skipped.
Hey Kris,
This is brilliant! I’ve always felt – and agree with you totally – that using native DOM API’s in a complementary way with browsers results to highly performant UI’s; no need for virtual DOM’s and all. The philosophy/approach behind Alkali is refreshing and has definitely gained my attention.